- Administración de datos distribuidos con distintos niveles de transparencia: En un marco ideal, todo sistema de base de datos debe ser una distribución transparente, para poder ocultar los detalles de dónde está físicamente ubicado cada fichero dentro del sistema. Existen varios tipos de transparencias:
- Transparencia de red o de distribución: Se refiere a la autonomía del usuario de los detalles operacionales de la red, dividido en transparencia de localización y de denominación. La transparencia de localización hace mención al hecho de que el comando usado para llevar a cabo una tarea es independiente de la ubicación de los datos y del sistema desde el que se ejecutó dicho comando. La transparencia de denominación implica que una vez especificado un nombre, se pueda acceder a los objetos nombrados sin ningún tipo de ambigüedad y sin la necesidad de especificaciones adicionales.
- Transparencia de replicación: Ésta permite que el usuario no se entere de la existencia de copias, las cuales pueden realizarse y almacenarse en distintos lugares para poder disponer de una mayor disponibilidad, rendimiento y fiabilidad.
- Transparencia de fragmentación: Existen dos tipos de fragmentación: la horizontal y la vertical. La horizontal distribuye una relación en conjunto de tuplas, mientras que la vertical lo hace en subrelaciones, de modo que cada subrelacion está definida por un subconjunto de las columnas de la relación original. En tal forma, la transparencia de fragmentación permite que el usuario no se entere de la existencia de fragmentos.
- Transparencia de diseño y de ejecución: Esto hace referencia a la libertad de saber cómo está diseñada la base de datos distribuida y dónde ejecuta una transacción.
- Incremento de la fiabilidad y disponibilidad: La fiabilidad es la probabilidad de que un sistema esté funcionando en un momento de tiempo, mientras que la disponibilidad es la probabilidad de que el sistema este continuamente disponible durante un intervalo de tiempo. Cuando los datos y el software de BD están distribuidos a lo largo de distintas locaciones, uno de ellos puede fallar, mientras que el resto debe seguir operativo.
- Rendimiento mejorado: un sistema de BD distribuido fragmenta la base de datos manteniendo la información lo más cerca posible del punto donde es más necesaria. Al distribuirse una BD, se obtienen BD mucho más pequeñas, haciendo que las consultas locales y las transacciones de acceso a los datos tenga un mayor rendimiento debido al menor tamaño de la base de datos.
- Expansión más sencilla: En un entorno distribuido, la expansión del sistema en términos de incorporación de más datos, incremento del tamaño de las bases de datos o la adición de más procesadores es mucho más sencilla.
miércoles, 14 de noviembre de 2012
Base de Datos Distribuidas
Consiste en un número de elementos de procesamiento, no necesariamente
homogéneos, que están interconectados mediante una red de computadores, y
que cooperan para la realización de ciertas tareas asignadas. El
objetivo de estos sistemas es el de dividir un gran e inmanejable
problema en piezas más pequeñas para resolverlo de una manera
coordinada. Son muchas las ventajas de las bases de datos distribuidas:
Arquitectura Cliente/Servidor
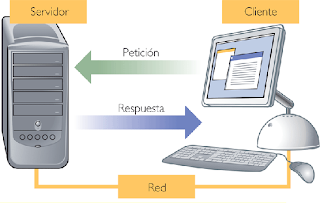
Se denomina cliente al proceso que inicia el diálogo o solicita los recursos y servidor, al proceso que responde a las solicitudes. Es el modelo de interacción más común entre aplicaciones en una red.
Por otro lado los clientes suelen ser estaciones de trabajo que solicitan varios servicios al servidor.Ambas partes deben estar conectadas entre sí mediante una red.
Beneficios.
1.- Mejor aprovechamiento de la potencia de cómputo (Reparte el trabajo).
2. -Reduce el tráfico en la Red. (Viajan requerimientos).
3.- Opera bajo sistemas abiertos.
4.- Permite el uso de interfaces gráficas variadas y versátiles.
Este tipo de arquitectura es la más utilizada en la actualidad, debido a que es la más avanzada y la que mejor ha evolucionado en estos últimos años.
Podemos decir que esta arquitectura necesita tres tipos de software para su correcto funcionamiento:
Software de gestión de datos: Este software se encarga de la manipulación y gestión de los datos almacenados y requeridos por las diferentes aplicaciones. Normalmente este software se aloja en el servidor.
Software de desarrollo: este tipo de software se aloja en los clientes y solo en aquellos que se dedique al desarrollo de aplicaciones.
Software de interacción con los usuarios: También reside en los clientes y es la aplicación gráfica de usuario para la manipulación de datos, siempre claro a nivel usuario (consultas principalmente).
Los Clientes interactúan con el usuario, usualmente en forma gráfica. Frecuentemente se comunican con procesos auxiliares que se encargan de establecer conexión con el servidor, enviar el pedido, recibir la respuesta, manejar las fallas y realizar actividades de sincronización y de seguridad.
caracteristicas:
• El Cliente oculta al Servidor y la Red.
• Detecta e intercepta peticiones de otras aplicaciones y puede redireccionarlas.
• Dedicado a la cesión del usuario ( Inicia…Termina ).
• El método más común por el que se solicitan los servicios es a través de RPC (Remote Procedure Calls).
funciones comunes del cliente:
• Mantener y procesar todo el dialogo con el usuario.
• Manejo de pantallas.
• Menús e interpretación de comandos.
• Entrada de datos y validación.
• Procesamiento de ayudas.
• Recuperación de errores.
• Generación de consultas e informes sobre las bases de datos.
el servidor:
Conjunto de Hardware y Software que responde a los requerimientos de un cliente. Los Servidores proporcionan un servicio al cliente y devuelven los resultados.
Normalmente el servidor es una máquina bastante potente que actúa de depósito de datos y funciona como un sistema gestor de base de datos (SGBD).
tipos comunes de servidor:
• Servidor de Archivos (FTP, Novell).
• Servidor de Bases de Datos (SQL, CBASE, ORACLE, INFORMIX).
• Servidor de Comunicaciones
• Servidor de Impresión.
• Servidor de Terminal.
• Servidor de Aplicaciones (Windows NT, Novell).
funciones comunes del servidor:
• Acceso, almacenamiento y organización de datos.
• Actualización de datos almacenados.
• Administración de recursos compartidos.
• Ejecución de toda la lógica para procesar una transacción.
• Procesamiento común de elementos del servidor (Datos, capacidad de CPU, almacenamiento en disco, capacidad de impresión, manejo de memoria y comunicación).
• Gestión de periféricos compartidos.
• Control de accesos concurrentes a bases de datos compartidas.
• Enlaces de comunicaciones con otras redes de área local o extensa
Base de Datos Centralizada
Es una base de datos almacenada en su totalidad en un solo lugar físico, es decir,
es una base de datos almacenada en una sola máquina y una sola CPU, y en donde los usuarios trabajan en terminales “tontas” que sólo muestran resultados.
Los sistemas de bases de datos centralizadas son
aquellos que se ejecutan en un único sistema informático sin
interaccionar con ninguna otra computadora. Tales sistemas
comprenden el rango desde los sistemas de base de datos monousuario
ejecutándose en computadoras personales hasta los
sistemas de bases de datos de alto rendimiento ejecutándose en grandes sistemas.
Arquitectura:
El
CPU y los controladores de dispositivos que pueden ejecutarse
concurrentemente, compitiendo así por el acceso a la memoria. La
memoria caché reduce la disputa por el acceso a la memoria, ya que el
CPU necesita acceder a la memoria, compartida un numero de
veces menor.
Se
distinguen dos formas de utilizar las computadoras: como sistemas
monousuario o multiusuario. En la primera categoría están las
computadoras personales y las estaciones de trabajo. Un sistema
monousuario típico es una unidad de sobremesa utilizada por una única
persona que dispone de una sola CPU, de uno o dos discos fijos y que
trabaja con un solo sistema operativo que
Solo
permite un único usuario. Por el contrario,
un sistema multiusuario típico tiene más discos y más memoria, puede
disponer de varias CPU y trabaja con un sistema operativo multiusuario.
Sistemas centralizados
Una
computadora moderna de propósito general consiste en una o unas pocas
unidades centrales de procesamiento y un número determinado de
controladores para los dispositivos que se encuentran conectados a
través de un bus común, el cual proporciona acceso a la memoria
compartida unidades centrales de procesamiento) poseen memorias caché
locales donde se almacenan copias de ciertas partes de la memoria para
acelerar el acceso a los datos.
Se distinguen dos formas de utilizar las computadoras:
como sistemas monousuario o multiusuario. En la primera categoría están las computadoras personales y las estaciones de trabajo.
Un sistema monousuario típico
es una unidad de sobremesa utilizada por una única persona que dispone
de una sola UCP, de uno o dos discos fijos y que trabaja con un sistema
operativo que sólo permite un único usuario. Por el contrario, un sistema multiusuario típico
tiene más discos y más memoria, puede disponer de varias UCP y trabaja
con un sistema operativo multiusuario. Se encarga de dar servicio a un
gran número de usuarios que están conectados al sistema a través de
terminales. Recuperacion de la Base de Datos
Una base de datos puede ser algo complicada que puede dañarse y por consecuencia perder información que se tiene guardada y echar por la borda días, meses o años de trabajo. Las pérdidas pueden ser diferentes como ejemplo, un disco defectuoso o volúmenes dañados. Las bases de datos son vulnerables y pueden sufrir corrupción. Cuando se produce algún daño en base de datos, el uso de las herramientas administrativas normales pueden causar daños mayores.
Uno de los elementos más importantes y críticos de las bases de datos es el log. Tanto SQL Server, DB2, Oracle, mySQL utilizan el log constantemente como herramienta de recuperación. En SQL Server tiene 2 funciones:
- Almacenar el histórico de todas las transacciones de la base de datos, principalmente para que los cambios de dichas transacciones se hagan en memoria y no en disco y funcione mucho más rápido (hay un proceso posterior llamado “Ahead Logging” que se encarga de guardar las páginas de memoria “sucias”, osea las que han cambiado a través de una transacción a fichero de datos físico de la base de datos.
- Servir como recuperación de la base de datos hasta el momento justo en que se cayó la base de datos.
En este post, vamos a ver el segundo supuesto de cómo SQL Server usa el log para recuperar la base de datos.
Para que la recuperación sea efectiva, el fichero de log debe estar en un disco duro a parte del fichero de datos de la base de datos. Eso hace que si falla el disco de datos, el fichero de log aún sea accesible, además de mejorar el rendimiento I/O general de la base de datos ya que no compiten el log y el fichero de datos por el acceso al mismo disco.
Imaginemos que hemos hecho la copia de seguridad a las 3:00 de la mañana de nuestra base de datos con una sentencia similar a esta:
backup database contabilidad to disk = ‘c:\backup\contabilidad.bak’ with init
Esta sentencia nos permite hacer una copia de seguridad de la base de datos contabilidad al fichero contabilidad.bak. El parámetro with init, simplemente indica que sino existe el fichero físico, lo cree de nuevo.
Ahora imaginemos que la base de datos está activa al día siguiente, la gente trabajando y justo antes de finalizar la jornada laboral, a las 17:00 de la tarde, el disco de datos del servidor falla y por tanto perdemos la base de datos. Vaya marrón….
Somos previsores, tenemos discos de repuestos y en media hora tenemos el servidor online otra vez, pero al arrancar el sql server, la base de datos de contabilidad no se pone en marcha… (lógico sino tenemos el fichero de datos).
 Vemos que el fichero de datos se ha perdido con lo que no puede
arrancar. Lo primero que pensamos es ir y restaurar la copia de
seguridad de la noche anterior (la de las 3 de la mañana que tenemos
automatizada). No sería una mala opción, pero pensemos que si hacemos
eso, perdemos todo lo que hemos hecho durante ese día. Pensemos que se
han metido ese día 1000 facturas… vaya marrón volverlas a meter todas….
Pensemos que hay entornos críticos que eso es inadmisible…
Vemos que el fichero de datos se ha perdido con lo que no puede
arrancar. Lo primero que pensamos es ir y restaurar la copia de
seguridad de la noche anterior (la de las 3 de la mañana que tenemos
automatizada). No sería una mala opción, pero pensemos que si hacemos
eso, perdemos todo lo que hemos hecho durante ese día. Pensemos que se
han metido ese día 1000 facturas… vaya marrón volverlas a meter todas….
Pensemos que hay entornos críticos que eso es inadmisible…
Una solución a este problema es utilizar el fichero de log. Si este fichero está en otro disco duro físico, entonces no habrá fallado y por tanto será accesible. Además este fichero, tendrá almacenados todo el histórico de todas las transacciones que se han hecho durante ese día, justo hasta el momento en que se cayó el sistema. Con SQL Server, podemos recuperar dicho log con esta sentencia:
backup log contabilidad to disk = ‘c:\backup\final.bak’ with init, no_truncate;
Fijémonos que aquí estamos haciendo copia del fichero log, no del de los datos y sobre todo, fijémonos en el parámetro no_truncate. Este parámetro le dice a SQL Server que no trunque el log y que por tanto copie la parte final del log desde la última copia de seguridad, osea desde las 3:00 de la mañana, hasta las 17:00 horas del día siguiente. Esto es lo que se denomina en SQL Server el “Tail log”, osea la parte final del log que contiene el histórico de transacciones desde la última copia de seguridad que se hizo (o desde la última copia de log si ha habido otras intermedias).
Una vez tenemos la parte final del log salvada, ya podemos hacer el restore de la base datos, osea la recuperación de la copia de la noche anterior con esta sentencia:
restore database contabilidad from disk = ‘c:\backup\contabilidad.bak’ with NORECOVERY;
Fijémonos que esto permitirá recuperar la base de datos hasta las 3 de la mañana que es cuando se hizo la última copia de seguridad. Fijémonos aún más importante el parámetro NORECOVERY. Este parámetro le dice a SQL Server que restaure los ficheros desde la copia de seguridad (el de datos y el log) pero que no haga la recuperación, osea que los deje tal y como están. De esta forma, le estamos diciendo a SQL Server que deje intacto el log, porque vamos a seguir restaurando parte de log, para volver hasta el momento en el que se cayó el sistema.
 Finalmente nos faltará restaurar la parte final del log (Tail-log)
que es la que contiene el histórico de transacciones desde las 3:00 de
la mañana hasta las 17:00 horas que es cuando cayó el sistema. Usaremos
una sentencia parecida a esta:
Finalmente nos faltará restaurar la parte final del log (Tail-log)
que es la que contiene el histórico de transacciones desde las 3:00 de
la mañana hasta las 17:00 horas que es cuando cayó el sistema. Usaremos
una sentencia parecida a esta:
restore log contabilidad from disk = ‘c:\backup\final.bak’ with RECOVERY;
Fijémonos que en esta sentencia, estamos recuperando el log y no el fichero de datos y además al final le indicamos con el parámetro RECOVERY, que precisamente haga la recuperación. Osea que vuelva a rehacer todas las transacciones que tiene en el log (desde las 3:00 de la mañana hasta las 17:00 de la tarde) y que deje la base de datos online.
 De esta forma, el marrón, se vuelve un marroncito pequeño, nadie
pierde nada y volvemos a tener la base de datos online sin perder nada
de información.
De esta forma, el marrón, se vuelve un marroncito pequeño, nadie
pierde nada y volvemos a tener la base de datos online sin perder nada
de información.
Uno de los elementos más importantes y críticos de las bases de datos es el log. Tanto SQL Server, DB2, Oracle, mySQL utilizan el log constantemente como herramienta de recuperación. En SQL Server tiene 2 funciones:
- Almacenar el histórico de todas las transacciones de la base de datos, principalmente para que los cambios de dichas transacciones se hagan en memoria y no en disco y funcione mucho más rápido (hay un proceso posterior llamado “Ahead Logging” que se encarga de guardar las páginas de memoria “sucias”, osea las que han cambiado a través de una transacción a fichero de datos físico de la base de datos.
- Servir como recuperación de la base de datos hasta el momento justo en que se cayó la base de datos.
En este post, vamos a ver el segundo supuesto de cómo SQL Server usa el log para recuperar la base de datos.
Para que la recuperación sea efectiva, el fichero de log debe estar en un disco duro a parte del fichero de datos de la base de datos. Eso hace que si falla el disco de datos, el fichero de log aún sea accesible, además de mejorar el rendimiento I/O general de la base de datos ya que no compiten el log y el fichero de datos por el acceso al mismo disco.
Imaginemos que hemos hecho la copia de seguridad a las 3:00 de la mañana de nuestra base de datos con una sentencia similar a esta:
backup database contabilidad to disk = ‘c:\backup\contabilidad.bak’ with init
Esta sentencia nos permite hacer una copia de seguridad de la base de datos contabilidad al fichero contabilidad.bak. El parámetro with init, simplemente indica que sino existe el fichero físico, lo cree de nuevo.
Ahora imaginemos que la base de datos está activa al día siguiente, la gente trabajando y justo antes de finalizar la jornada laboral, a las 17:00 de la tarde, el disco de datos del servidor falla y por tanto perdemos la base de datos. Vaya marrón….
Somos previsores, tenemos discos de repuestos y en media hora tenemos el servidor online otra vez, pero al arrancar el sql server, la base de datos de contabilidad no se pone en marcha… (lógico sino tenemos el fichero de datos).

Base de datos de SQL Server Inaccesible
Una solución a este problema es utilizar el fichero de log. Si este fichero está en otro disco duro físico, entonces no habrá fallado y por tanto será accesible. Además este fichero, tendrá almacenados todo el histórico de todas las transacciones que se han hecho durante ese día, justo hasta el momento en que se cayó el sistema. Con SQL Server, podemos recuperar dicho log con esta sentencia:
backup log contabilidad to disk = ‘c:\backup\final.bak’ with init, no_truncate;
Fijémonos que aquí estamos haciendo copia del fichero log, no del de los datos y sobre todo, fijémonos en el parámetro no_truncate. Este parámetro le dice a SQL Server que no trunque el log y que por tanto copie la parte final del log desde la última copia de seguridad, osea desde las 3:00 de la mañana, hasta las 17:00 horas del día siguiente. Esto es lo que se denomina en SQL Server el “Tail log”, osea la parte final del log que contiene el histórico de transacciones desde la última copia de seguridad que se hizo (o desde la última copia de log si ha habido otras intermedias).
Una vez tenemos la parte final del log salvada, ya podemos hacer el restore de la base datos, osea la recuperación de la copia de la noche anterior con esta sentencia:
restore database contabilidad from disk = ‘c:\backup\contabilidad.bak’ with NORECOVERY;
Fijémonos que esto permitirá recuperar la base de datos hasta las 3 de la mañana que es cuando se hizo la última copia de seguridad. Fijémonos aún más importante el parámetro NORECOVERY. Este parámetro le dice a SQL Server que restaure los ficheros desde la copia de seguridad (el de datos y el log) pero que no haga la recuperación, osea que los deje tal y como están. De esta forma, le estamos diciendo a SQL Server que deje intacto el log, porque vamos a seguir restaurando parte de log, para volver hasta el momento en el que se cayó el sistema.

Base de datos de SQL Server en modo NO RECOVERY
restore log contabilidad from disk = ‘c:\backup\final.bak’ with RECOVERY;
Fijémonos que en esta sentencia, estamos recuperando el log y no el fichero de datos y además al final le indicamos con el parámetro RECOVERY, que precisamente haga la recuperación. Osea que vuelva a rehacer todas las transacciones que tiene en el log (desde las 3:00 de la mañana hasta las 17:00 de la tarde) y que deje la base de datos online.

Base de datos de SQL Server recuperada y online
Seguridad de la Base de Datos
La gran mayoría de los datos sensibles del mundo están almacenados en
sistemas gestores de bases de datos comerciales tales como Oracle,
Microsoft SQL Server entre otros, y atacar una bases de datos es uno de
los objetivos favoritos para los criminales.
Esto puede explicar por qué los ataques externos, tales como
inyección de SQL, subieron 345% en 2009, “Esta tendencia es prueba
adicional de que los agresores tienen éxito en hospedar páginas Web
maliciosas, y de que las vulnerabilidades y explotación en relación a
los navegadores Web están conformando un beneficio importante para
ellos”. Para empeorar las cosas, según un estudio publicado en febrero de
2009 The Independent Oracle Users Group (IOUG), casi la mitad de todos
los usuarios de Oracle tienen al menos dos parches sin aplicar en sus
manejadores de bases de datos.
Mientras que la atención generalmente se ha centrado en asegurar los
perímetros de las redes por medio de, firewalls, IDS / IPS y antivirus,
cada vez más las organizaciones se están enfocando en la seguridad de
las bases de datos con datos críticos, protegiéndolos de intrusiones y
cambios no autorizados.
En las siguientes secciones daremos las siete recomendaciones para proteger una base de datos en instalaciones tradicionales.
Principios básicos de seguridad de bases de datos
En esta sección daremos siete
recomendaciones sobre seguridad en bases de datos, instaladas en
servidores propios de la organización.
- Identifique su sensibilidad
No se puede asegurar lo que no se conoce.
Confeccione un buen catálogo de tablas o datos sensibles de sus
instancias de base de datos. Además, automatice el proceso de
identificación, ya que estos datos y su correspondiente ubicación pueden
estar en constante cambio debido a nuevas aplicaciones o cambios
producto de fusiones y adquisiciones.
Desarrolle o adquiera herramientas de identificación, asegurando
éstas contra el malware, colocado en su base de datos el resultado
de los ataques de inyección SQL; pues aparte de exponer información
confidencial debido a vulnerabilidades, como la inyección SQL, también
facilita a los atacantes incorporar otros ataques en el interior de la
base de datos.
- Evaluación de la vulnerabilidad y la configuración
Evalúe su configuración de bases de datos, para asegurarse que no tiene huecos de seguridad.
Evalúe su configuración de bases de datos, para asegurarse que no tiene huecos de seguridad.
Esto incluye la verificación de la forma en que se instaló la base de
datos y su sistema operativo (por ejemplo, la comprobación privilegios
de grupos de archivo -lectura, escritura y ejecución- de base de datos y
bitácoras de transacciones).
Asimismo con archivos con parámetros de configuración y programas ejecutables.
Además, es necesario verificar que no se está ejecutando la base de
datos con versiones que incluyen vulnerabilidades conocidas; así como
impedir consultas SQL desde las aplicaciones o capa de usuarios. Para
ello se pueden considerar (como administrador):
- Limitar el acceso a los procedimientos a ciertos usuarios.
- Delimitar el acceso a los datos para ciertos usuarios, procedimientos y/o datos.
- Declinar la coincidencia de horarios entre usuarios que coincidan.
- Endurecimiento
Como resultado de una evaluación de la vulnerabilidad a menudo se dan
una serie de recomendaciones específicas. Este es el primer paso en el
endurecimiento de la base de datos. Otros elementos de endurecimiento
implican la eliminación de todas las funciones y opciones que se no
utilicen. Aplique una política estricta sobre que se puede y que no se
puede hacer, pero asegúrese de desactivar lo que no necesita.
- Audite
Una vez que haya creado una configuración y controles de
endurecimiento, realice auto evaluaciones y seguimiento a las
recomendaciones de auditoría para asegurar que no se desvíe de su
objetivo (la seguridad).
Automatice el control de la configuración de tal forma que se
registre cualquier cambio en la misma. Implemente alertas sobre cambios
en la configuración. Cada vez que un cambio se realice, este podría
afectar a la seguridad de la base de datos.
- Monitoreo
Monitoreo en tiempo real de la actividad de base de datos es clave
para limitar su exposición, aplique o adquiera agentes inteligentes
de monitoreo, detección de intrusiones y uso indebido.
Por ejemplo, alertas sobre patrones inusuales de acceso, que podrían
indicar la presencia de un ataque de inyección SQL, cambios no
autorizados a los datos, cambios en privilegios de las cuentas, y los
cambios de configuración que se ejecutan a mediante de comandos de SQL.
Recuerde que el monitoreo usuarios privilegiados, es requisito para
la gobernabilidad de datos y cumplimiento de regulaciones como SOX
y regulaciones de privacidad. También, ayuda a detectar intrusiones, ya
que muchos de los ataques más comunes se hacen con privilegios de
usuario de alto nivel.
El monitoreo dinámico es también un elemento esencial de la
evaluación de vulnerabilidad, le permite ir más allá de evaluaciones
estáticas o forenses. Un ejemplo clásico lo vemos cuando múltiples
usuarios comparten credenciales con privilegios o un número excesivo de
inicios de sesión de base de datos.
- Pistas de Auditoría
Aplique pistas de auditoría y genere trazabilidad de las actividades
que afectan la integridad de los datos, o la visualización los datos
sensibles.
Recuerde que es un requisito de auditoría, y también es importante para las investigaciones forenses.
La mayoría de las organizaciones en la actualidad emplean alguna
forma de manual de auditoría de transacciones o aplicaciones nativas de
los sistemas gestores de bases de datos. Sin embargo, estas
aplicaciones son a menudo desactivadas, debido a:
- su complejidad
- altos costos operativos
- problemas de rendimiento
- la falta de segregación de funciones y
- la necesidad mayor capacidad de almacenamiento.
Afortunadamente, se han desarrollado soluciones con un mínimo de impacto en el rendimiento y poco costo operativo, basado en tecnologías de agente inteligente.
- Autenticación, control de acceso, y Gestión de derechos
No todos los datos y no todos los usuarios son creados iguales. Usted
debe autenticar a los usuarios, garantizar la rendición de cuentas por
usuario, y administrar los privilegios para de limitar el acceso a los
datos.
Implemente y revise periódicamente los informes sobre de derechos de usuarios, como parte de un proceso de formal de auditoría.
Utilice el cifrado para hacer ilegibles los datos confidenciales,
complique el trabajo a los atacantes, esto incluye el cifrado de los
datos en tránsito, de modo que un atacante no puede escuchar en la capa
de red y tener acceso a los datos cuando se envía al cliente de base de
datos.
Integridad y Concurrencia
Integridad
La integridad en una base de datos es la corrección y exactitud
de la información que posee la misma. Además de ello, busca la seguridad en un
sistema de bases de datos que permita el acceso a múltiples usuarios en tiempos
paralelos.
Las condiciones que garantizan la integridad de los datos
pueden ser de dos tipos:
- Las restricciones de integridad de usuario: son condiciones específicas de una base de datos concreta que se deben cumplir con unos usuarios concretos.
- Las reglas de integridad de modelo: son condiciones propias de un modelo de datos, y se deben cumplir en toda base de datos que siga dicho modelo.
Los SGBD deben proporcionar la forma de definir
las restricciones de integridad de usuario de una base de datos y una vez
definida, procurar que se cumplan. Las reglas de integridad del modelo, en
cambio, no se deben definir para cada base de datos concreta, porque se
consideran preestablecidas para todas las base de datos de un modelo.
Reglas de Integridad.-
Regla de integridad de unicidad de la clave primaria
Hace referencia a que los valores de una clave primaria no
pueden repetirse entre los atributos de una misma tabla.
Regla de integridad de entidad de la clave primaria
La regla de integridad de entidad de la clave primaria
dispone que los atributos de la clave primaria de una relación no puede tener
valores nulos.
Regla de integridad referencial
La regla de integridad referencial está relacionada con el
concepto de clave foránea, lo que determina que todos los valores que toma una
clave foránea deben ser valores nulos o valores que existen en la clave
primaria que referencia.
Restricción
La restricción en caso de borrado, consiste en no permitir
borrar una tupla si tiene una clave primaria referenciada por alguna clave
foránea y la restricción en caso de modificación consiste en no permitir
modificar ningún atributo de la clave primaria de una fila si tiene una clave
primaria representada por alguna clave foránea.
Actualización en cascada
La actualización en cascada consiste en permitir la
operación de actualización de la tupla, y en efectuar operaciones que propaguen
en cascada la actualización a las tuplas que la referenciaban; se actúa de este
modo para mantener la integridad referencial.
Anulación
La anulación consiste en permitir la operación de
actualización de la tupla y en efectuar operaciones que pongan valores nulos a
los atributos de la clave foránea de las tuplas que la referencian; esta acción
se lleva a cabo para mantener la integridad referencial.
Concurrencia
El termino concurrencia se refiere al hecho de que los
DBMS (SISTEMAS DE ADMINISTRACION DE BD) permiten que muchas transacciones
puedan realizarse en una misma base de datos a la vez. Para este sistema se
necesita algún mecanismo de control para que las operaciones simultáneas no
interfieran entre sí.

Métodos de control de concurrencia
Protocolos basados en técnicas de bloqueo
Un bloqueo es una operación usada para restringir las
operaciones que se pueden aplicar sobre la base de datos. Existen varios
tipos de bloqueo: binarios, compartidos, exclusivos, y bloqueos de
certificación.
Bloqueos binarios
Poseen dos valores posibles, bloqueados y
desbloqueados. Cada elemento de la base de datos tiene un bloqueo
distinto. El bloqueo señala si una transacción está en ejecución sobre el
elemento o está libre para que se pueda operar con él.
Bloqueos de lectura/escritura
Puede tener tres posibles posiciones: libre, bloqueado
para lectura, y bloqueado para escritura. De esta forma, más de una transacción
puede tener un mismo elemento de datos bloqueado para lectura, pero sólo una
para escritura.
Problemas del bloqueo en dos fases: interbloqueo y
espera indefinida
El interbloqueo se produce cuando una transacción T1 está
esperando a algún elemento que está bloqueado por otra transacción T2. De esta
forma, cada transacción está parada en espera a que otra transacción libere el
recurso.
- Exclusión mutua.- Cada elemento está bloqueado o está libre por una transacción.
- Retención y espera.- Una transacción que ya ha bloqueado elementos puede solicitar un elemento adicional, y esperar que se le asigne, sin habilitar ninguno de los elementos anteriores.
- No apropiación.- La transacción sólo puede liberar un elemento que tenga asignado; no se lo puede quitar a otra transacción que tenga mayor prioridad.
- Espera circular.- Existe una cadena circular, compuesta por dos transacciones o más, y otros tantos elementos intercalados, de manera que cada proceso está esperando que se le asigne un elemento, el cual, a su vez, está asignado al siguiente proceso de la cadena.
- Bloqueo mutuo o deadlock.- Un proceso se encuentra en estado de deadlock si está esperando por un suceso que no ocurrirá nunca.
Administración de Objetos y Recursos
Las bases de datos orientadas a objetos es aquella que está
constituida por objetos, que pueden ser de muy diferentes tipos, sobre las
cuales se encuentran definidas operaciones. Incorpora los conceptos importantes
del modelo de objetos: Encapsulación, Herencia y Polimorfismo. Es en este tipo
de bases de datos que los usuarios pueden definir operaciones sobre los datos
como parte de la definición de datos. La orientación a objetos ofrece
flexibilidad y no está limitada por los tipos de datos y los lenguajes de
consulta de los sistemas de bases de datos tradicionales.
Los objetos estructurados se agrupan en clases. No es necesaria una transformación del modelo
de objetos hecho en un lenguaje de programación distinto pues las clases serán las
mismas que en el modelo de bases de datos. Se requiere mucha abstracción para
convertir objetos del mundo real a tablas en el modelo. Cabe resaltar que
muchas organizaciones desean utilizar esta tecnología orientada a objetos.

Administración
de objetos
Retomando el
tema del interés de las empresas por utilizar esta tecnología, cabe resaltar
que muchas de ellas utilizan un modelo de base de datos relacional y el proceso
para migrarla a una base de datos orientada a objetos es la siguiente:

- - Crear una interface orientada a objetos encima de la base de datos relacional. No existe interrupción del sistema para la migración de datos y no existe perdida semántica de la información.
- - Los datos deben ser migrados de acuerdo con el motor de base de datos (por ejemplo Oracle 7 a 8), y las características orientadas a objetos solo pueden ser explotadas con la modificación o extensión del esquema.
- - La migración de la base de datos en donde un nuevo esquema bajo el OODBMS es creado y los datos son migrados de la base de datos relacional a la orientada a objetos.
En las bases
de datos orientadas a objetos existen ciertos paradigmas:
- - Encapsulación: Propiedad que permite hacer privada u oculta alguna información al resto de los objetos, impidiendo algunos conflictos posteriores.
- - Herencia: Propiedad a través de la cual los objetos heredan comportamientos de otra tabla padre.
- - Polimorfismo: Propiedad de una operación mediante la cual, ésta puede ser aplicada a distintos tipos de objetos.
En bases de datos orientadas a objetos, los usuarios pueden
definir operaciones sobre los datos como parte de la definición de la base de
datos. Estas operaciones reciben el nombre de funciones, las cuales se dividen
en dos partes: interfaz y tipo de datos a usar. La implementación, también
llamada método, de la operación se especifica separadamente y puede modificarse
sin afectar la interfaz.
Administración
de recursos
Los datos son
los principales recursos con los que cuenta una base de datos. El
almacenamiento de los mismos es la tendencia más importante en la
administración de la información en las organizaciones, pero al ser amplia la
cantidad de datos que podemos encontrar en el entorno se presentan problemas,
los cuales merecen atención:

- - La cantidad de datos que se maneja puede ser enorme, ya que las organizaciones cuentan con datos ya almacenados, estos deben permanecer a pesar de los constantes nuevos ingresos de datos al sistema.
- - Existen datos dispersados en muchas organizaciones, en diferentes métodos y dispositivos de recopilación.
- - Solo una parte de todos los datos que se recolectan dan la utilidad que espera obtener de ellos.
- - Para lograr eficiencia en la toma de decisiones, es necesario recurrir a datos externos ya que los conseguidos no dan la información que se necesita.
- - Los datos en bruto, son en muchas ocasiones de difícil acceso, ya que están almacenados en diferentes sistemas de cómputo, bases de datos, formatos, lenguajes humanos y de computador.
- - Las leyes relativas a los datos obtenidos, pueden diferir de un lugar a otro para su aplicación, así los datos conseguidos no pueden tener aplicabilidad global.
- - Se pueden presentar problemas de seguridad, calidad e integridad con la recopilación y el análisis de datos.
- - Existen problemas con la administración de datos por el gigante número de estos disponibles.
Suscribirse a:
Comentarios (Atom)